
The scandal in the meat factories area and the answer to why the next and new problem with food is suddenly emerging. Listex P100 and the controversial application. Listx P100 has been approved in Europe and around the world for many years. Listex P100 is a genome, a virus, yes Listex P100 is also Covid19. Let’s ask those responsible! We eat sick and with the approval of the governments, cheers ….. have you ever seen this or a similar picture of the virus Covid19?

Listex P100: Zulassung für alle Nahrungsmittel
Dekontamination von Fleisch, Fisch und Milch im Hinblick auf Listeria monocytogenes
Commission Regulation on the use of Listex™ P100 against Listeria in ready-to-eat food products
Listex™ P100 for reduction of pathogens on different ready-to-eat (RTE) food products
Listeria virus P100 is a virus of the family Herelleviridae, genus Pecentumvirus.
Listeria virus P100 has been proposed as food additive to control Listeria monocytogenes, the bacteria responsible for Listeriosis. Listeriosis is an infection that is the result of consuming food that is contaminated by Listeria monocytogenes.

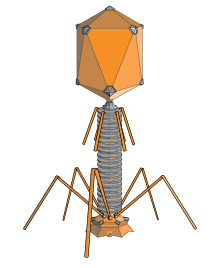
As a member of the group I of the Baltimore classification, Listeria virus P100 is a dsDNA virus. P100 shares a nonenveloped morphology consisting of a head and a tail separated by a neck similar to other members of the Myoviridae family. Virions are independent particles that exist separate from cells. They are spread by attaching to a host cell and injecting a double stranded DNA; the host then transcribes and translates it to manufacture new particles. Host cell DNA polymerases is needed to replicate its genetic content, therefore, the process is highly dependent on the cell cycle.
Characteristics
Listeria virus P100 targets Listeria monocytogenes, the bacterial pathogen responsible for listeriosis.Listeria monocytogenes is the only human pathogen that causes Listeriosis. Unlike most phages infecting bacteria in the genus Listeria, Listeria virus P100 is a virulent phage. This means that it destroys the host cell through lysis which is when the membrane of a cell is broken down. This makes phage P100 absolutely lethal to Listeria after infection. The contractile tail of the Listeria virus P100 serves as the mechanism in which DNA is ejected from the (non-encased) protein capsid into the host’s cytoplasm, where DNA replication occurs independently from the host. Additionally, the P100 type has a very large host range, which accounts for over 95% of all bacteria types within Listeria that appear in food (unlike most phages in its genus.)
Treatment potential
Listeriosis affects approximately 1,600 people each year, and within that group about 260 people will not survive. Listeriosis is most commonly observed in immunocompromised, pregnant, elderly or young people. Listeria monocytogenes can grow on a variety of foods, such as cheese, meat, poultry, vegetables, and seafood. Listeria monocytogenes may even be detected on surfaces that have had contact with the previously mentioned foods. Listeria virus P100 has been shown to be generally stable under storage conditions. Listeria virus P100 is a key component to the food additive Listex P100, which has received GRAS (generally recognized as safe) status by the US food and drug administration and is currently approved for use in the European Union as well. PhageGuard is a company that developed an organic, FDA approved product to combat Listeria. The company prides themselves on not affecting the smell, texture or taste of the food they use their product on while eliminating Listeria monocytogenes.
Genome
Its linear genome contains 131,385 base pairs that encode 174 open reading frames and 18 tRNAs. The requirement for each open reading frame (ORF) was the presence of one of the following start codons: ATG, TTG, or GTG as well as a suitable ribosomal binding site and a minimum length of 40 encoded amino acids.
P100 appears to be closely related to Listeria virus A511, which is also virulent. Both belong morphologically to the Herelleviridae family. Further phenotypic observations also correlate well, showing significant nucleotide homologies between them. There are also some shared sequences with other Herelleviridae phages that infect Gram-Positive bacteria.
Bacteriophage
A bacteriophage, also known informally as a phage, is a virus that infects and replicates within bacteria and archaea. The term was derived from „bacteria“ and the Greek φαγεῖν (phagein), meaning „to devour“. Bacteriophages are composed of proteins that encapsulate a DNA or RNA genome, and may have structures that are either simple or elaborate. Their genomes may encode as few as four genes (e.g. MS2) and as many as hundreds of genes. Phages replicate within the bacterium following the injection of their genome into its cytoplasm.
Bacteriophages are among the most common and diverse entities in the biosphere. Bacteriophages are ubiquitous viruses, found wherever bacteria exist. It is estimated there are more than 1031 bacteriophages on the planet, more than every other organism on Earth, including bacteria, combined. One of the densest natural sources for phages and other viruses is seawater, where up to 9×108 virions per millilitre have been found in microbial mats at the surface, and up to 70% of marine bacteria may be infected by phages.
Phages have been used since the late 20th century as an alternative to antibiotics in the former Soviet Union and Central Europe, as well as in France. They are seen as a possible therapy against multi-drug-resistant strains of many bacteria (see phage therapy). On the other hand, phages of Inoviridae have been shown to complicate biofilms involved in pneumonia and cystic fibrosis and to shelter the bacteria from drugs meant to eradicate disease, thus promoting persistent infection.
Genome
In the fields of molecular biology and genetics, a genome is the genetic material of an organism. It consists of DNA (or RNA in RNA viruses). The genome includes both the genes (the coding regions) and the noncoding DNA, as well as mitochondrial DNA and chloroplast DNA. The study of the genome is called genomics.
Origin of term
The term genome was created in 1920 by Hans Winkler, professor of botany at the University of Hamburg, Germany. The Oxford Dictionary suggests the name is a blend of the words gene and chromosome. However, see omics for a more thorough discussion. A few related -ome words already existed, such as biome and rhizome, forming a vocabulary into which genome fits systematically.
Genome project
Genome projects are scientific endeavours that ultimately aim to determine the complete genome sequence of an organism (be it an animal, a plant, a fungus, a bacterium, an archaean, a protist or a virus) and to annotate protein-coding genes and other important genome-encoded features. The genome sequence of an organism includes the collective DNA sequences of each chromosome in the organism. For a bacterium containing a single chromosome, a genome project will aim to map the sequence of that chromosome. For the human species, whose genome includes 22 pairs of autosomes and 2 sex chromosomes, a complete genome sequence will involve 46 separate chromosome sequences.
The Human Genome Project was a landmark genome project that is already having a major impact on research across the life sciences, with potential for spurring numerous medical and commercial developments.
Sequencing and mapping
A genome sequence is the complete list of the nucleotides (A, C, G, and T for DNA genomes) that make up all the chromosomes of an individual or a species. Within a species, the vast majority of nucleotides are identical between individuals, but sequencing multiple individuals is necessary to understand the genetic diversity.
Part of DNA sequence – prototypification of complete genome of virus
In 1976, Walter Fiers at the University of Ghent (Belgium) was the first to establish the complete nucleotide sequence of a viral RNA-genome (Bacteriophage MS2). The next year, Fred Sanger completed the first DNA-genome sequence: Phage Φ-X174, of 5386 base pairs.The first complete genome sequences among all three domains of life were released within a short period during the mid-1990s: The first bacterial genome to be sequenced was that of Haemophilus influenzae, completed by a team at The Institute for Genomic Research in 1995. A few months later, the first eukaryotic genome was completed, with sequences of the 16 chromosomes of budding yeast Saccharomyces cerevisiae published as the result of a European-led effort begun in the mid-1980s. The first genome sequence for an archaeon, Methanococcus jannaschii, was completed in 1996, again by The Institute for Genomic Research.
The development of new technologies has made genome sequencing dramatically cheaper and easier, and the number of complete genome sequences is growing rapidly. The US National Institutes of Health maintains one of several comprehensive databases of genomic information. Among the thousands of completed genome sequencing projects include those for rice, a mouse, the plant Arabidopsis thaliana, the puffer fish, and the bacteria E. coli. In December 2013, scientists first sequenced the entire genome of a Neanderthal, an extinct species of humans. The genome was extracted from the toe bone of a 130,000-year-old Neanderthal found in a Siberian cave.
New sequencing technologies, such as massive parallel sequencing have also opened up the prospect of personal genome sequencing as a diagnostic tool, as pioneered by Manteia Predictive Medicine. A major step toward that goal was the completion in 2007 of the full genome of James D. Watson, one of the co-discoverers of the structure of DNA.
Whereas a genome sequence lists the order of every DNA base in a genome, a genome map identifies the landmarks. A genome map is less detailed than a genome sequence and aids in navigating around the genome. The Human Genome Project was organized to map and to sequence the human genome. A fundamental step in the project was the release of a detailed genomic map by Jean Weissenbach and his team at the Genoscope in Paris.
Reference genome sequences and maps continue to be updated, removing errors and clarifying regions of high allelic complexity. The decreasing cost of genomic mapping has permitted genealogical sites to offer it as a service, to the extent that one may submit one’s genome to crowdsourced scientific endeavours such as DNA.LAND at the New York Genome Center, an example both of the economies of scale and of citizen science.
Viral genomes
Viral genomes can be composed of either RNA or DNA. The genomes of RNA viruses can be either single-stranded or double-stranded RNA, and may contain one or more separate RNA molecules (segments: monopartit or multipartit genome). DNA viruses can have either single-stranded or double-stranded genomes. Most DNA virus genomes are composed of a single, linear molecule of DNA, but some are made up of a circular DNA molecule.
Prokaryotic genomes
Prokaryotes and eukaryotes have DNA genomes. Archaea have a single circular chromosome. Most bacteria also have a single circular chromosome; however, some bacterial species have linear chromosomes or multiple chromosomes. If the DNA is replicated faster than the bacterial cells divide, multiple copies of the chromosome can be present in a single cell, and if the cells divide faster than the DNA can be replicated, multiple replication of the chromosome is initiated before the division occurs, allowing daughter cells to inherit complete genomes and already partially replicated chromosomes. Most prokaryotes have very little repetitive DNA in their genomes. However, some symbiotic bacteria (e.g. Serratia symbiotica) have reduced genomes and a high fraction of pseudogenes: only ~40% of their DNA encodes proteins.
Some bacteria have auxiliary genetic material, also part of their genome, which is carried in plasmids. For this, the word genome should not be used as a synonym of chromosome.
Eukaryotic genomes
Eukaryotic genomes are composed of one or more linear DNA chromosomes. The number of chromosomes varies widely from Jack jumper ants and an asexual nemotode, which each have only one pair, to a fern species that has 720 pairs. A typical human cell has two copies of each of 22 autosomes, one inherited from each parent, plus two sex chromosomes, making it diploid. Gametes, such as ova, sperm, spores, and pollen, are haploid, meaning they carry only one copy of each chromosome.
In addition to the chromosomes in the nucleus, organelles such as the chloroplasts and mitochondria have their own DNA. Mitochondria are sometimes said to have their own genome often referred to as the „mitochondrial genome“. The DNA found within the chloroplast may be referred to as the „plastome“. Like the bacteria they originated from, mitochondria and chloroplasts have a circular chromosome.
Unlike prokaryotes, eukaryotes have exon-intron organization of protein coding genes and variable amounts of repetitive DNA. In mammals and plants, the majority of the genome is composed of repetitive DNA.
Coding sequences
DNA sequences that carry the instructions to make proteins are coding sequences. The proportion of the genome occupied by coding sequences varies widely. A larger genome does not necessarily contain more genes, and the proportion of non-repetitive DNA decreases along with increasing genome size in complex eukaryotes.
Simple eukaryotes such as C. elegans and fruit fly, have more non-repetitive DNA than repetitive DNA, while the genomes of more complex eukaryotes tend to be composed largely of repetitive DNA. In some plants and amphibians, the proportion of repetitive DNA is more than 80%. Similarly, only 2% of the human genome codes for proteins.
Composition of the human genome
Noncoding sequences
Noncoding sequences include introns, sequences for non-coding RNAs, regulatory regions, and repetitive DNA. Noncoding sequences make up 98% of the human genome. There are two categories of repetitive DNA in the genome: tandem repeats and interspersed repeats.
Tandem repeats
Short, non-coding sequences that are repeated head-to-tail are called tandem repeats. Microsatellites consisting of 2-5 basepair repeats, while minisatellite repeats are 30-35 bp. Tandem repeats make up about 4% of the human genome and 9% of the fruit fly genome. Tandem repeats can be functional. For example, telomeres are composed of the tandem repeat TTAGGG in mammals, and they play an important role in protecting the ends of the chromosome.
In other cases, expansions in the number of tandem repeats in exons or introns can cause disease. For example, the human gene huntingtin typically contains 6–29 tandem repeats of the nucleotides CAG (encoding a polyglutamine tract). An expansion to over 36 repeats results in Huntington’s disease, a neurodegenerative disease. Twenty human disorders are known to result from similar tandem repeat expansions in various genes. The mechanism by which proteins with expanded polygulatamine tracts cause death of neurons is not fully understood. One possibility is that the proteins fail to fold properly and avoid degradation, instead accumulating in aggregates that also sequester important transcription factors, thereby altering gene expression.
Tandem repeats are usually caused by slippage during replication, unequal crossing-over and gene conversion.
Transposable elements
Transposable elements (TEs) are sequences of DNA with a defined structure that are able to change their location in the genome. TEs are categorized as either class I TEs, which replicate by a copy-and-paste mechanism, or class II TEs, which can be excised from the genome and inserted at a new location.
The movement of TEs is a driving force of genome evolution in eukaryotes because their insertion can disrupt gene functions, homologous recombination between TEs can produce duplications, and TE can shuffle exons and regulatory sequences to new locations.
Retrotransposons
Retrotransposons can be transcribed into RNA, which are then duplicated at another site into the genome.
Retrotransposons can be divided into long terminal repeats (LTRs) and non-long terminal repeats (Non-LTRs).
Long terminal repeats (LTRs) are derived from ancient retroviral infections, so they encode proteins related to retroviral proteins including gag (structural proteins of the virus), pol (reverse transcriptase and integrase), pro (protease), and in some cases env (envelope) genes. These genes are flanked by long repeats at both 5′ and 3′ ends. It has been reported that LTRs consist of the largest fraction in most plant genome and might account for the huge variation in genome size.
Non-long terminal repeats (Non-LTRs) are classified as long interspersed nuclear elements (LINEs), short interspersed nuclear elements (SINEs), and Penelope-like elements (PLEs). In Dictyostelium discoideum, there is another DIRS-like elements belong to Non-LTRs. Non-LTRs are widely spread in eukaryotic genomes.
Long interspersed elements (LINEs) encode genes for reverse transcriptase and endonuclease, making them autonomous transposable elements. The human genome has around 500,000 LINEs, taking around 17% of the genome.
Short interspersed elements (SINEs) are usually less than 500 base pairs and are non-autonomous, so they rely on the proteins encoded by LINEs for transposition. The Alu element is the most common SINE found in primates. It is about 350 base pairs and occupies about 11% of the human genome with around 1,500,000 copies.
DNA transposons
DNA transposons encode a transposase enzyme between inverted terminal repeats. When expressed, the transposase recognizes the terminal inverted repeats that flank the transposon and catalyzes its excision and reinsertion in a new site. This cut-and-paste mechanism typically reinserts transposons near their original location (within 100kb). DNA transposons are found in bacteria and make up 3% of the human genome and 12% of the genome of the roundworm C. elegans
Genome size
Log-log plot of the total number of annotated proteins in genomes submitted to GenBank as a function of genome size.
Genome size is the total number of DNA base pairs in one copy of a haploid genome. In humans, the nuclear genome comprises approximately 3.2 billion nucleotides of DNA, divided into 24 linear molecules, the shortest 50 000 000 nucleotides in length and the longest 260 000 000 nucleotides, each contained in a different chromosome. The genome size is positively correlated with the morphological complexity among prokaryotes and lower eukaryotes; however, after mollusks and all the other higher eukaryotes above, this correlation is no longer effective. This phenomenon also indicates the mighty influence coming from repetitive DNA on the genomes.
Since genomes are very complex, one research strategy is to reduce the number of genes in a genome to the bare minimum and still have the organism in question survive. There is experimental work being done on minimal genomes for single cell organisms as well as minimal genomes for multi-cellular organisms (see Developmental biology). The work is both in vivo and in silico.